5.1 Simple Linear Regression
I will not go much in details with what simple linaer regression is.
One can calculate the beta values by the following
\[\begin{equation} b_0=\ \overline{Y}-\ b_1\overline{X} \tag{5.1} \end{equation}\]
\[\begin{equation} b_1=\frac{\sum_{ }^{ }\left(X-\overline{X}\right)\left(Y-\overline{Y}\right)}{\sum_{ }^{ }\left(X-\overline{X}\right)^{^2}} \tag{5.2} \end{equation}\]
Where point forecast, hence \(\hat{Y}\) is merely the sum of the linear equation, hence \(\hat{Y}=b_0+b_1X^*\), where \(X^*\) is the specific X values. Thence one can estimate the standard error by:
\[\begin{equation} s_{yx}=\sqrt{\frac{\sum_{ }^{ }\left(Y-\overline{Y}\right)^{^2}}{n-2}} \tag{5.3} \end{equation}\]
Equations (5.3) can also be written otherwise, see the slides for that.
The residuals can be broken down to the following
\[\begin{equation} \sum_{ }^{ }\left(Y-\overline{Y}\right)^{^2}=\sum_{ }^{ }\left(\hat{Y}-\ \overline{Y}\right)^{^2}+\sum_{ }^{ }\left(Y-\ \hat{Y}\right)^{^2} \tag{5.4} \end{equation}\]
Which consist of the following three elements.
\[\begin{equation} SST = SSR + SSE \tag{5.5} \end{equation}\]
The residuals can then be applied for a goodness of fit assessment, where one can identify R squared-
\[\begin{equation} R^2=\frac{SSR}{SST} \tag{5.5} \end{equation}\]
So what can the linear regression then be used for?
- Inference
- Prediction
Notice, that inference can only be done when the model is adequate, hence the assumptions actually being met.
5.1.1 Assumptions
We have the following assumptions for a linear model:
- The underlying relationship between dependent and independent variable is actually linear
- Independent residuals
- Homoskedastic residuals (show constant variance)
- Identically distributed (In general, normal distribution is assumed)
Hence how is the assumptions tested?
Some can be done before analysis and others after the model is applied, hence it can be described by the following:
- Before the model is applied:
- The underlying relationship between dependent and independent variable is actually linear
- After the model is applied (doing diagnostics):
- Independent residuals
- Homoskedastic residuals (show constant variance)
- Identically distributed (In general, normal distribution is assumed)
Now lets dive into the data
Serial correlation and Heteroskedasticity
Notice that autocorrelation = serial correlation
Serial correlation is where the observations are trailing each other, where heteroskedasticity is where the variance is changing over timer:
5.1.1.1 Serial correlation (checking for independent residuals):
We must make sure that the residuals does not have a clear pattern, as that means that some variables has been omitted. This can be assessed for example by:
- Visual inspection
- Durbin Watson test, see equation (5.6)
- Correlogram
- Statistical test for relationship between residuals and lagged residuals
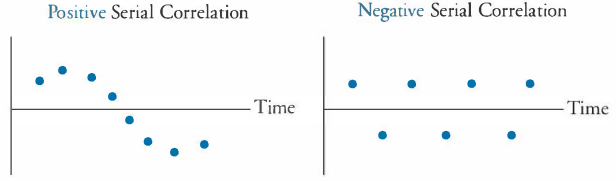
Figure 5.1: Serial Correlation Example
Notice, that one should also test for autocorrelation in the errors, that can be done with a Durbin-Watson statistic:
\[\begin{equation} DW\ =\frac{\sum_{ }^{ }\left(e_t-e_{t-1}\right)^{^2}}{\sum_{ }^{ }e_t^{^2}} \tag{5.6} \end{equation}\]
0 < DW < 4, where if DW = 2 it indicates no serial correlation (this is the ideal), generally if 1.5 < DW < 2.5 is widely used as an acceptable level.
If DW > 2, it indicates negative serial correlation and if DW < 2, it indicates that there is positive serial correlation.
One could also use correlation testing by checking correlogram of residuals or testing residuals against lagged residuals
Solution
- Try with lagging the variables
5.1.1.2 Heteroskedasticity:
We want the variance to have a constant variance. This can be checked visually, where we dont want to see a funnel shape, as in the visualization below.
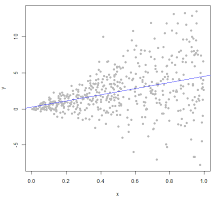
Figure 5.2: Heteroskedasticity Example
This can also be tested with a Breusch-Pagan Test, where the null hypothesis is that all errors are equal, hence null hypothesis, is that the errors are homoskedastic.
Solution
- Try lagging the variables
- Try applying differences in the observations
If one observe heteroskedasticity and can’t get rid of it, then one can apply a generalized least squares method. Although this introduce a set of new assumptions.
5.1.2 Forecasting with a linear trend
If the data contain a linear trend, then we are able to make the model account for this trend.
Hence we are able to detrend the data, by including a counter as a variable.
Another solution may be to using the differences in the observations, e.g., using growth rates.
This is important, as if one don’t detrend the data, then the model will merely describe the trend and not the actual values behind the trend, thus you want the model to account for the trend
5.1.3 Exercises
5.1.3.1 Problems 5 pp. 209
df <- read_excel("Data/Week46/prob5p209.xlsx")
plot(x = df$Age,y = df$MaintenanceCost,) + grid(col = "lightgrey") + abline(reg = lm(MaintenanceCost ~ Age,data = df))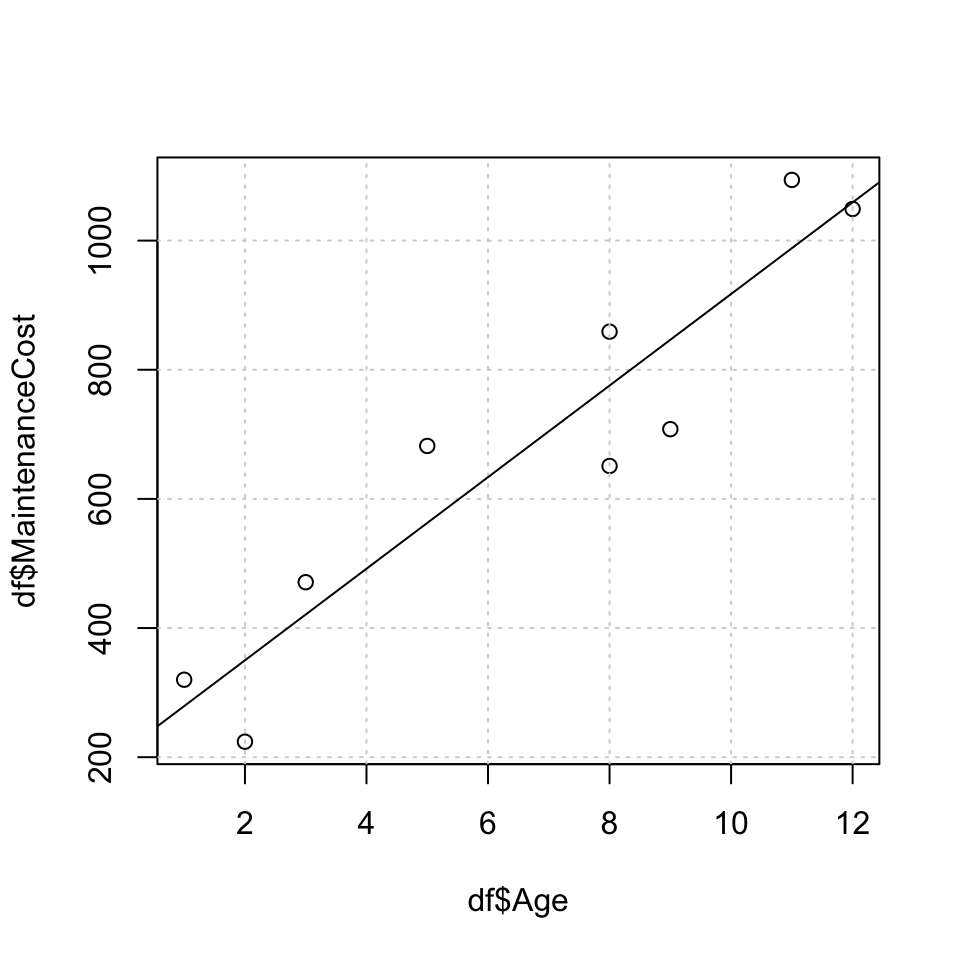
## integer(0)coef(object = lm(MaintenanceCost ~ Age,data = df))## (Intercept) Age
## 208.20335 70.91813If age is the dependent variable We see that the intercept is - 1.78, indicating that if there are no maintenance costs, then the age of the vehicle is -1.78 years old, which is naturally not possible, hence we see that the linear relathionship indicates that there will always be maintenance costs.
If maintenance cost is the dependent variable We see that the intercept is 208, hence there will be a begin maintenance of 208, which will always be there, and then for each year, it is expected to increase with about 71.
We can then test to see if the relationship is significant from a statistic point of view.
lm(Age ~ .,data = df) %>% summary()##
## Call:
## lm(formula = Age ~ ., data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.6658 -1.0498 -0.7737 1.0125 2.0119
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.789563 1.268264 -1.411 0.201098
## MaintenanceCost 0.012398 0.001737 7.139 0.000187 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.476 on 7 degrees of freedom
## Multiple R-squared: 0.8792, Adjusted R-squared: 0.862
## F-statistic: 50.96 on 1 and 7 DF, p-value: 0.0001872We see that there is statistical evidence to say that the relationship is linear. Also the coefficient of determination is 86% hence 86 of the variance is explained by the x variable.
Now we can do the diagnostics:
plot(lm(Age ~ .,data = df))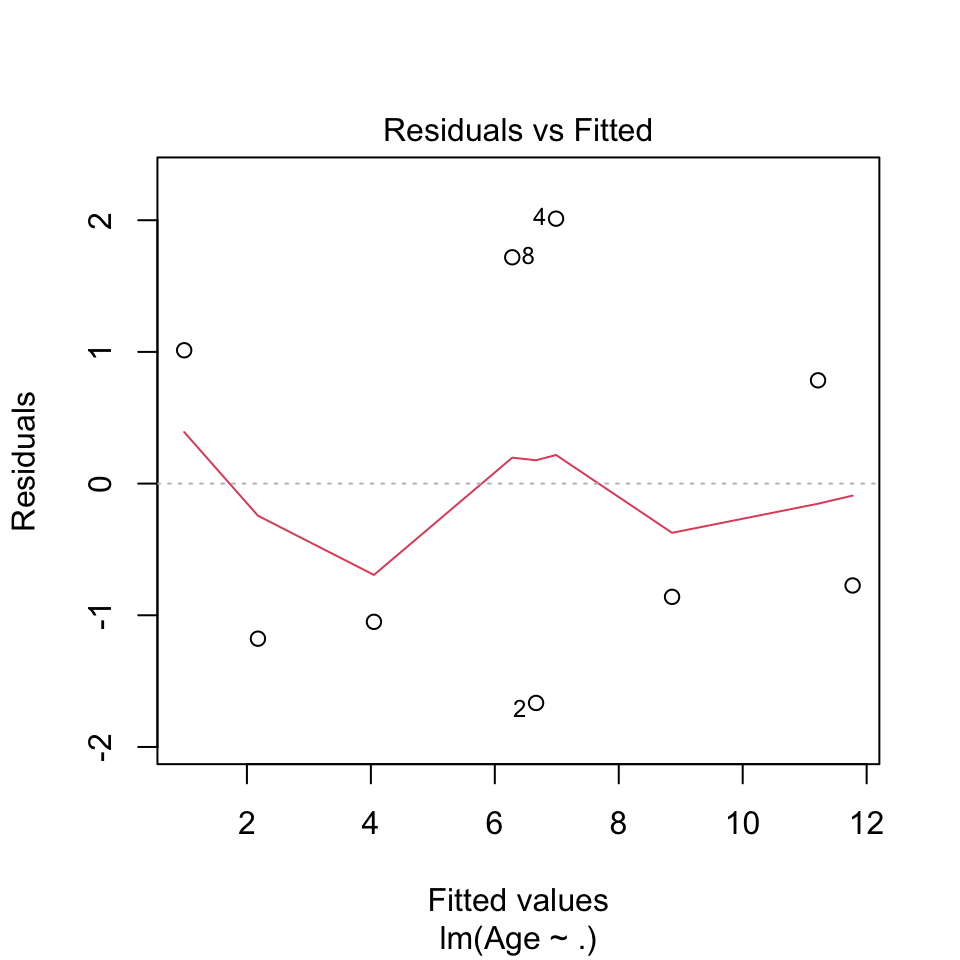
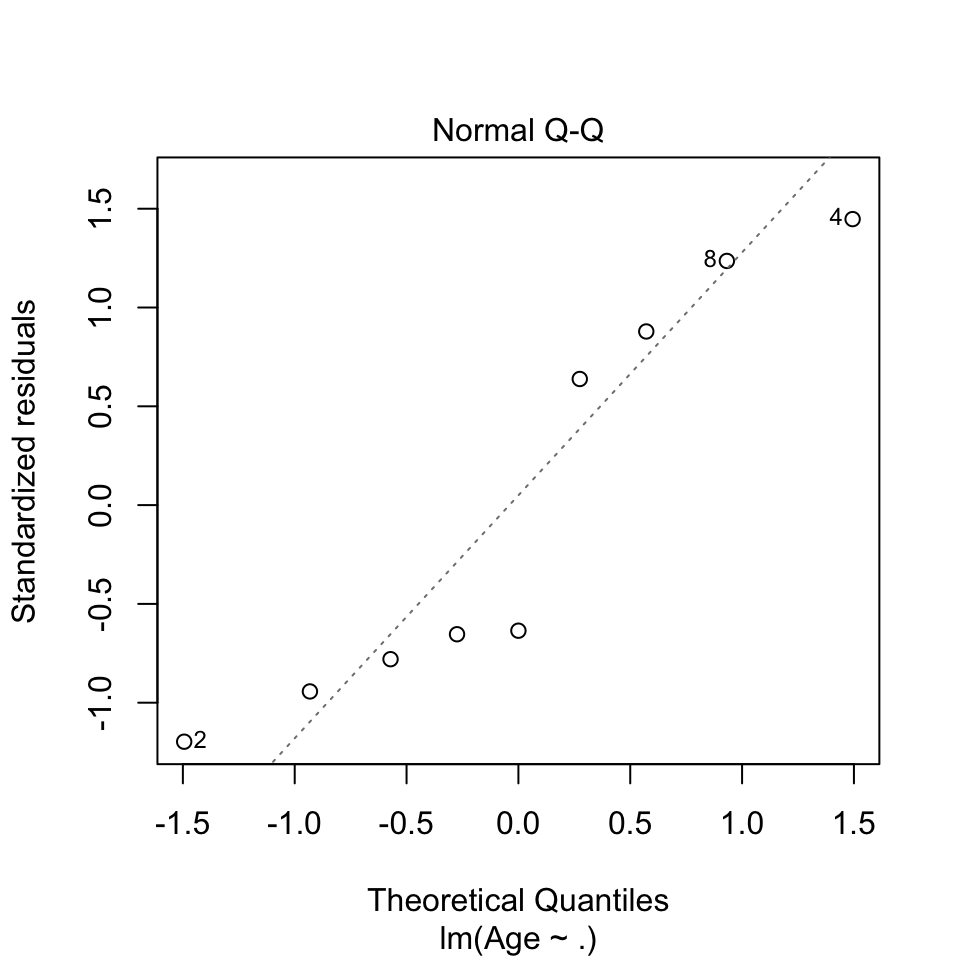
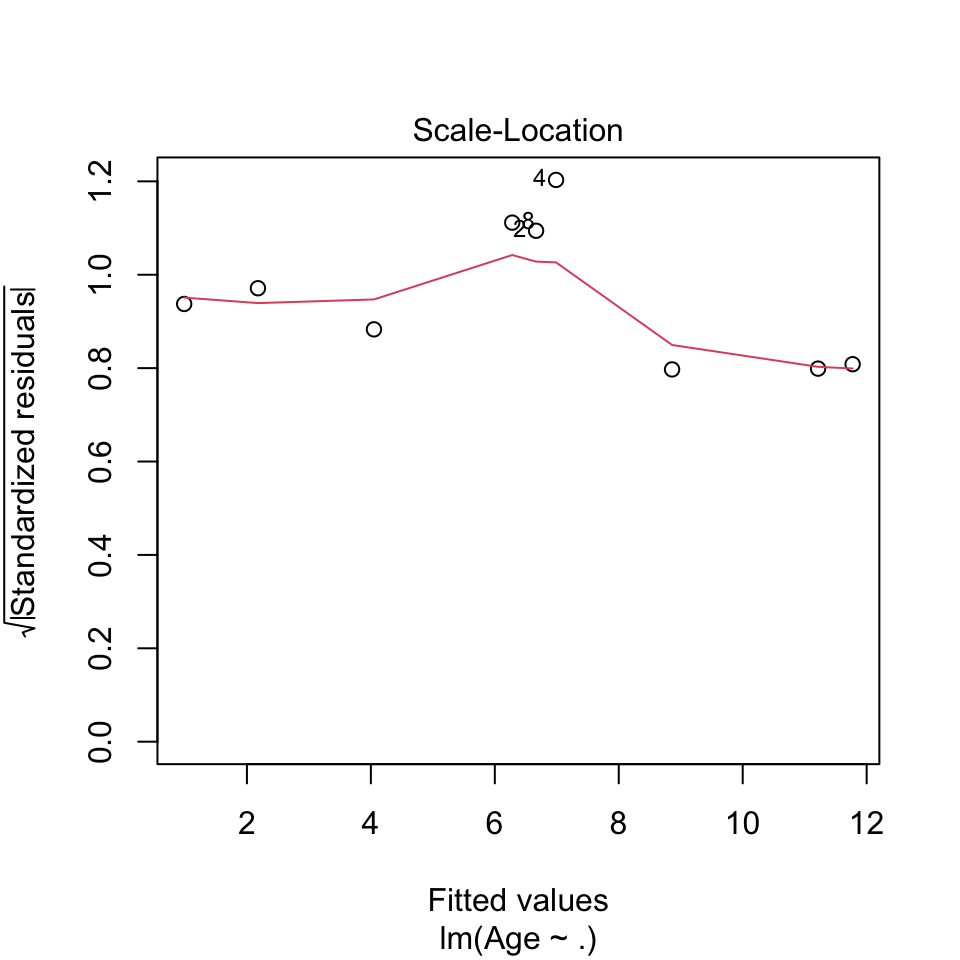
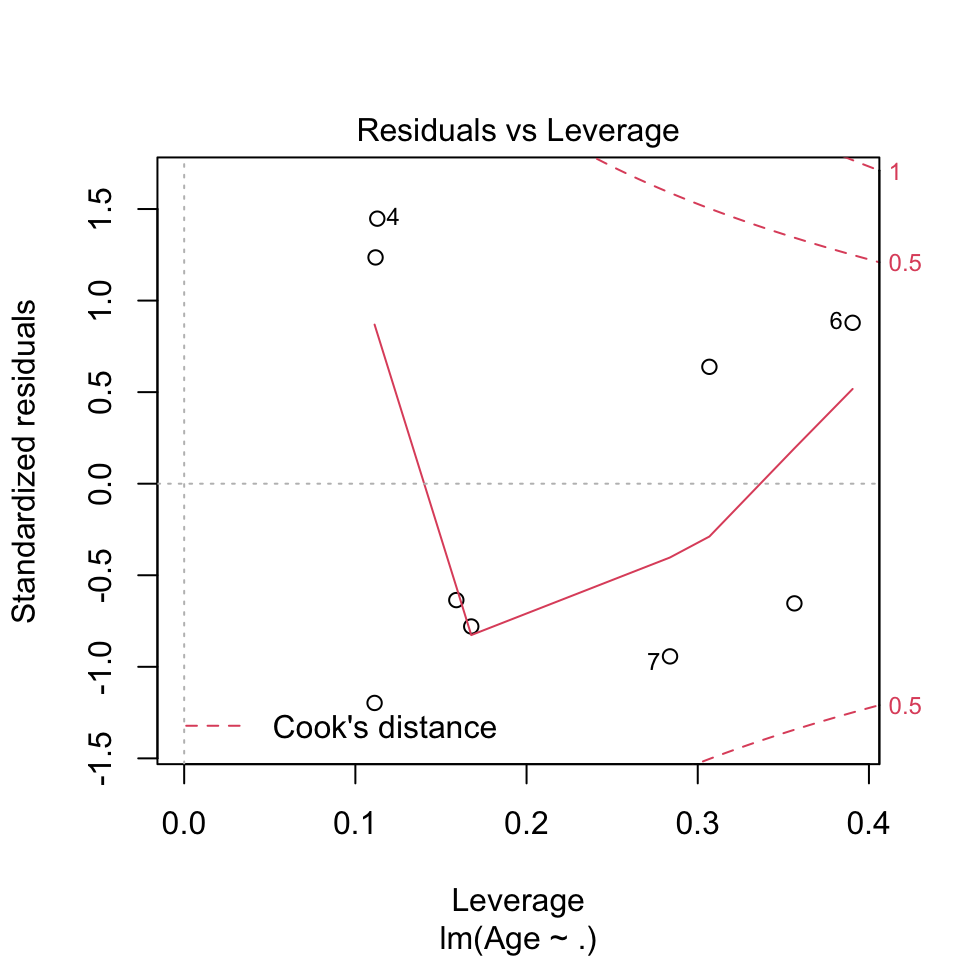
- Before the model is applied:
- The underlying relationship between dependent and independent variable is actually linear, This we must assume
- After the model is applied (doing diagnostics):
- Independent residuals We dont say any indication that the residuals are not independent.
- Homoskedastic residuals (show constant variance) The variance appear to be constant
- Identically distributed (In general, normal distribution is assumed) This we must assume
rm(list = ls())5.1.3.2 Problem 11 p. 212 HW
5.1.3.3 Cases 2 HW
Notice that the X is deviations from 65 degrees, as 65 degrees is the ideal for the production, hence when one read 10 degrees, then it is in fact 75 degrees or 55. Notice that the deviation is in absolut values.
df <- read_excel("Data/Week46/Case2p222.xlsx")
#head(df) #To see the first observations in each
Y <- df$Y
X <- df$X
scatter.smooth(x=X, y=Y, main="Y ~ X")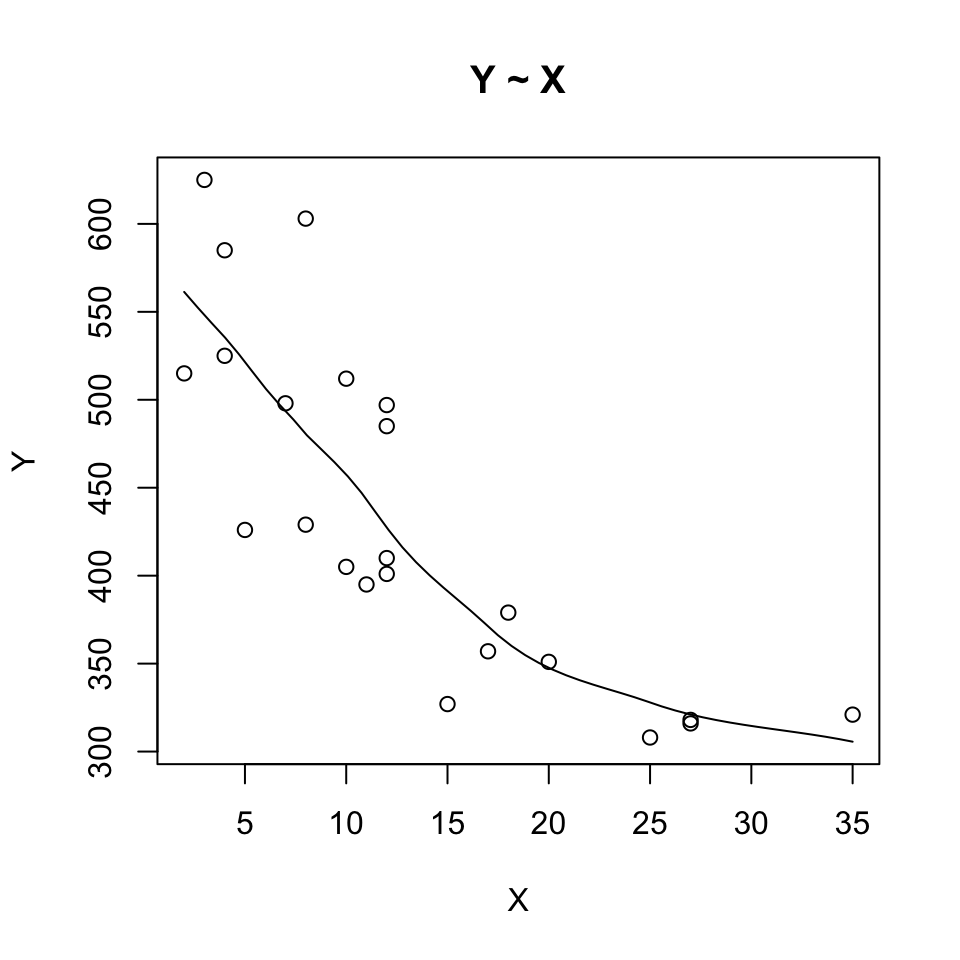
Figure 5.3: Plotting the model
cor(Y, X)## [1] -0.8010968We see that the correlation is negative, hence -0.8
linMod <- lm(Y ~ X) #To omit intercept when necessary, the formula can be written for example as lm(cost ~ age - 1)
summary(linMod)##
## Call:
## lm(formula = Y ~ X)
##
## Residuals:
## Min 1Q Median 3Q Max
## -91.38 -43.83 -12.64 44.48 122.25
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 552.040 22.851 24.158 < 2e-16 ***
## X -8.911 1.453 -6.133 4.37e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 59.41 on 21 degrees of freedom
## Multiple R-squared: 0.6418, Adjusted R-squared: 0.6247
## F-statistic: 37.62 on 1 and 21 DF, p-value: 4.374e-06We see an R square of 62.47 indicating that the linear relationship is not describing the relationship in the sample data very well, which the illustration above also show quite well.
plot(resid(linMod))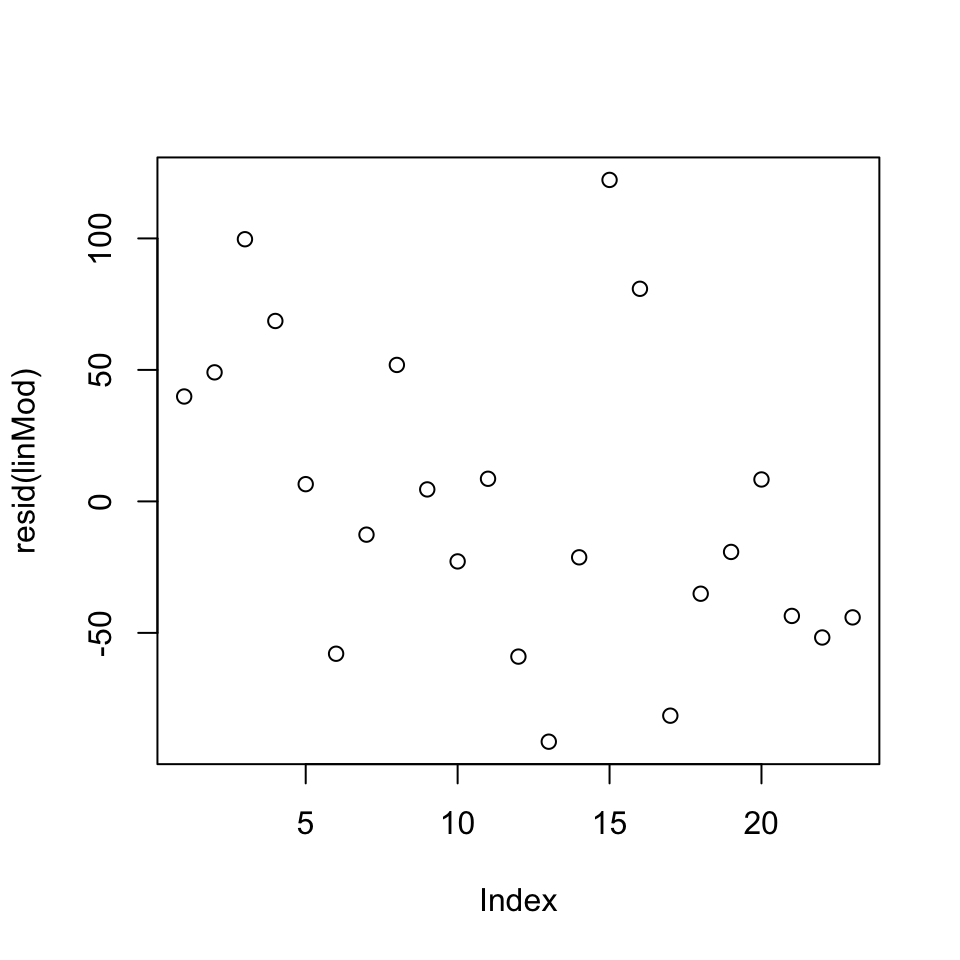
Figure 5.4: Residuals Case 2
Now we can assess if the data show autocorrelation. That can be done by using the acf()
acf(resid(linMod)) # white noise residuals?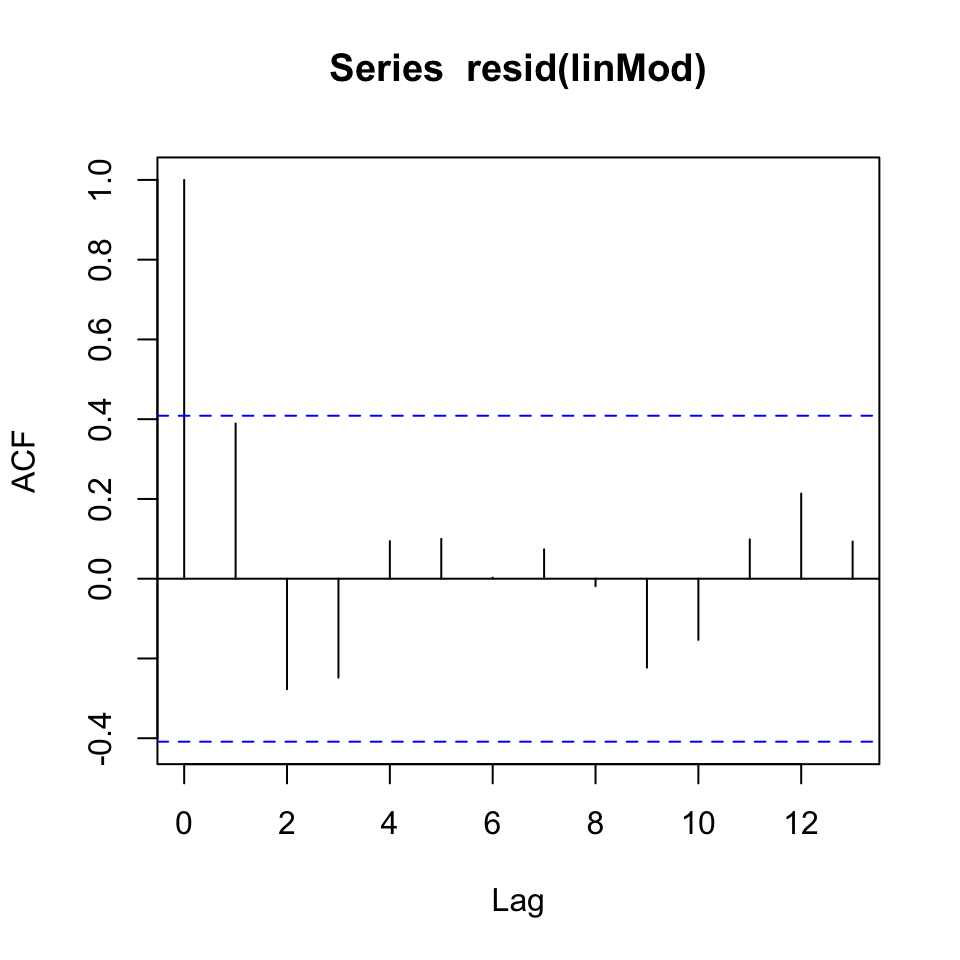
Figure 5.5: Correlogram
The data appear to show white noise, although there appear to be some pattern, which may show seasons in the data.
We can test to see if the residuals actually show constant variance, of the variance is not constant (heteroskedasticity)
bptest(linMod) # Breusch-Pagan test H_0: variance is constant.##
## studentized Breusch-Pagan test
##
## data: linMod
## BP = 1.069, df = 1, p-value = 0.3012Since the p value is not significant, there is not enough evidance to reject the null hypothesis, hence we may assume that the residuals show constant variance.
{ AIC(linMod) %>% print()
BIC(linMod) %>% print()}## [1] 257.0604
## [1] 260.4669We see the different information criteria, but we need other models to assess what is good and what is bad.
Q1 How many units would your forecast for a day in which the high temperatire is 80 degrees
a <- data.frame(X=24) #65+24=89 degrees
predict(linMod, a) %>% print()## 1
## 338.1778Hence we may expect 338 units to be produced on a day with 89 degrees.
Q2
When the degrees is 41, hence also a deviation of 24 degrees.
Q3 Is the forecasting tool effective?
We saw earlier that 80% of the variance is explained, although there is probably room for optimization
rm(list = ls())5.1.3.4 Case 3 from HW
df <- read_excel("Data/Week46/Case2p222.xlsx")
#head(df) #To see the first observations in each
Y <- df$Y
X <- df$X
plot(X,Y)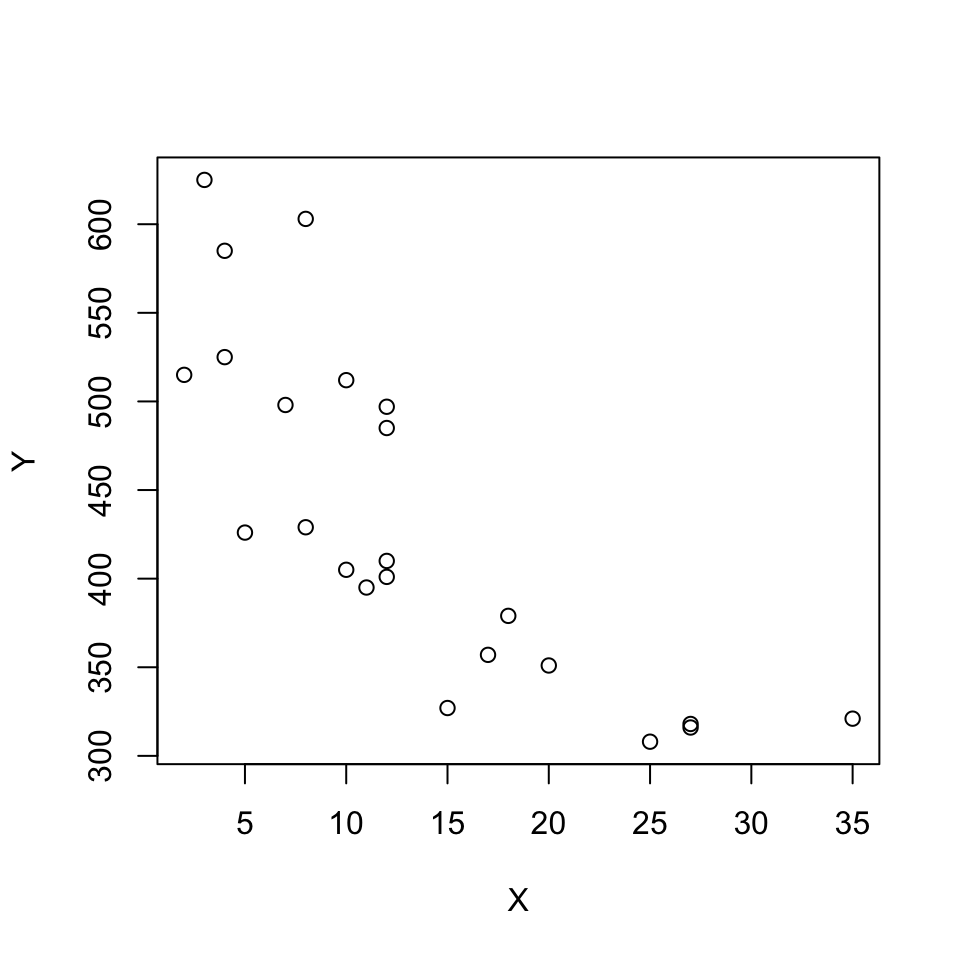
cor(Y, X)## [1] -0.8010968We see that the correlation is negative, hence -0.8
cor.test(Y,X)##
## Pearson's product-moment correlation
##
## data: Y and X
## t = -6.1335, df = 21, p-value = 4.374e-06
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.9121082 -0.5806250
## sample estimates:
## cor
## -0.80109685.1.3.5 Detrending thorugh regression: CO2
CO2levels <- read_excel("Data/Week46/CO2levels(1).xlsx")
y <- ts(CO2levels, frequency = 12) #Monthly series, so we specify the frequency=12.
trend <- seq(1:length(y)) #Creating the linear trend, simply a counter
plot(y)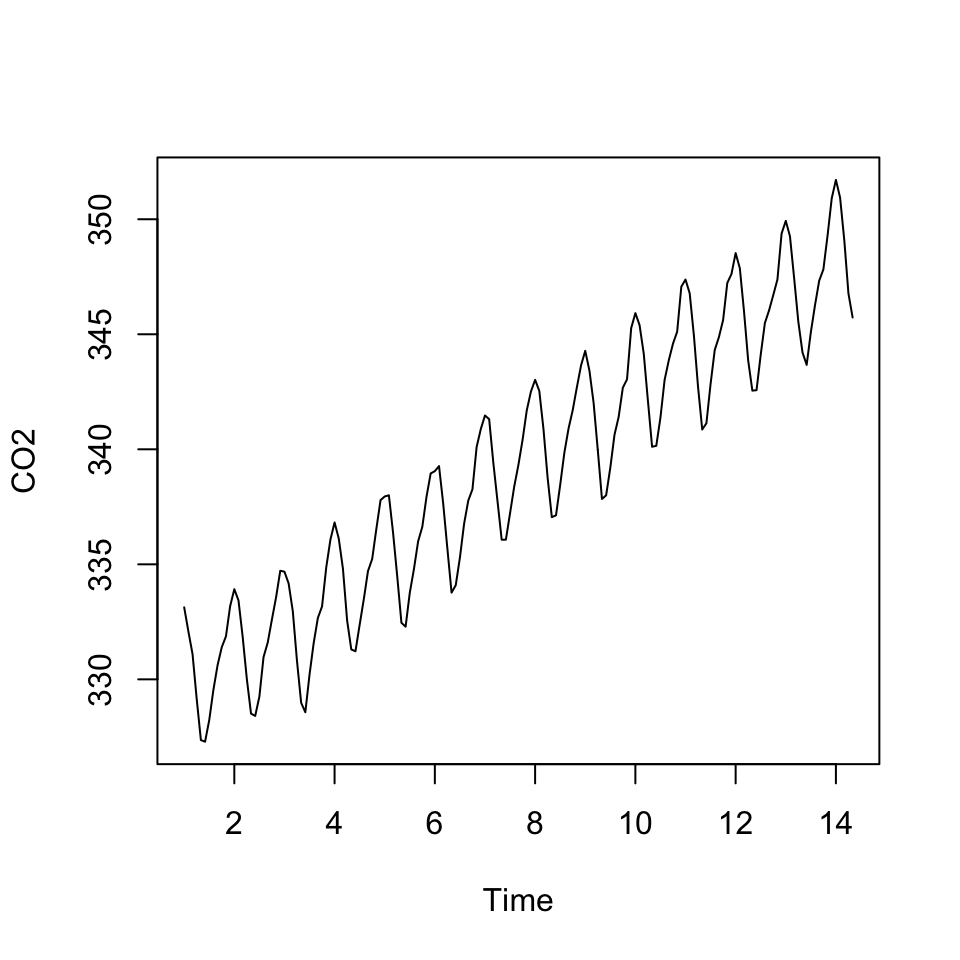
Figure 5.6: CO2 data
We see that there is a trend and cycles. This we want to get rid of, by enabling the model to account for that.
fit <- lm(y ~ trend)
summary(fit)##
## Call:
## lm(formula = y ~ trend)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.392 -1.866 0.199 2.190 3.677
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.293e+02 3.462e-01 951.40 <2e-16 ***
## trend 1.210e-01 3.707e-03 32.64 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.186 on 159 degrees of freedom
## Multiple R-squared: 0.8701, Adjusted R-squared: 0.8693
## F-statistic: 1065 on 1 and 159 DF, p-value: < 2.2e-16
ystar <- resid(fit) #ystar is the detrended series, which is simply the residuals from the previous regression.
plot(ystar) + lines(ystar, col="red")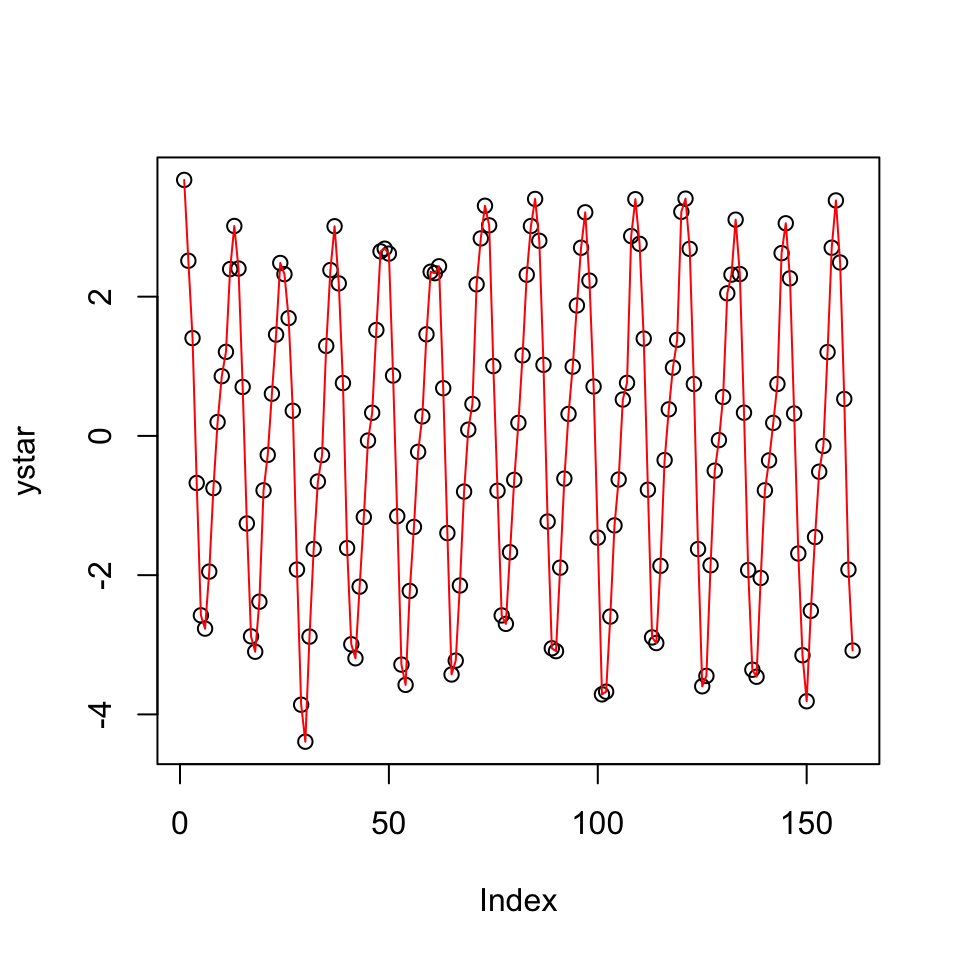
Figure 5.7: Detrended series
## integer(0)Now wee see that the data show constant variance and appear to be stationary around a mean of 0.
But did we get rid of the seasonality?
To compare, one can print the detrended and the initial data.
par(mfrow = c(2,1))
acf(y, 50)
acf(x = ystar,lag.max = 50) #We can specify how many lags we want to plot. Here I just chose 50. 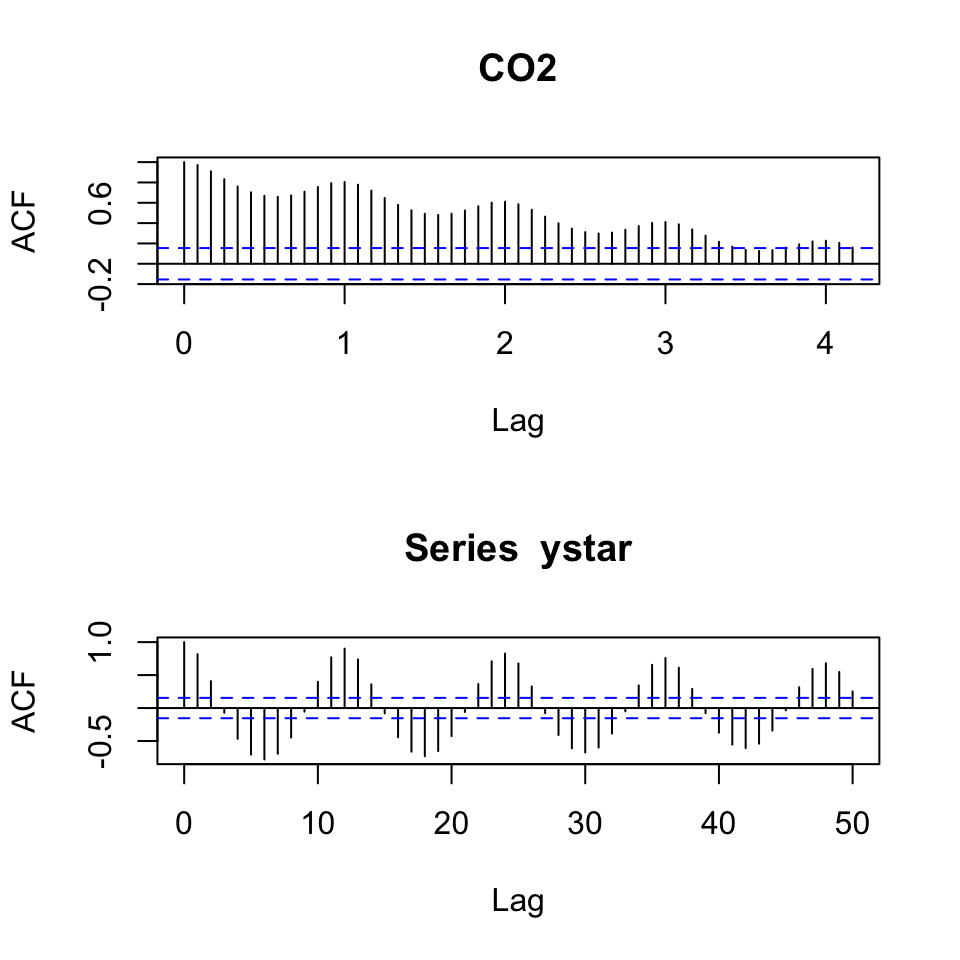
Figure 5.8: Correlogram comparison detrended
Hence we see that we got rid of the trend, but still see that there is great seasonality in the data.
Alternative to detrending –> differencing
An alternative to detrending with the trend variable, is to using differencing
dy <- diff(x = y,lag = 1)
plot(dy) #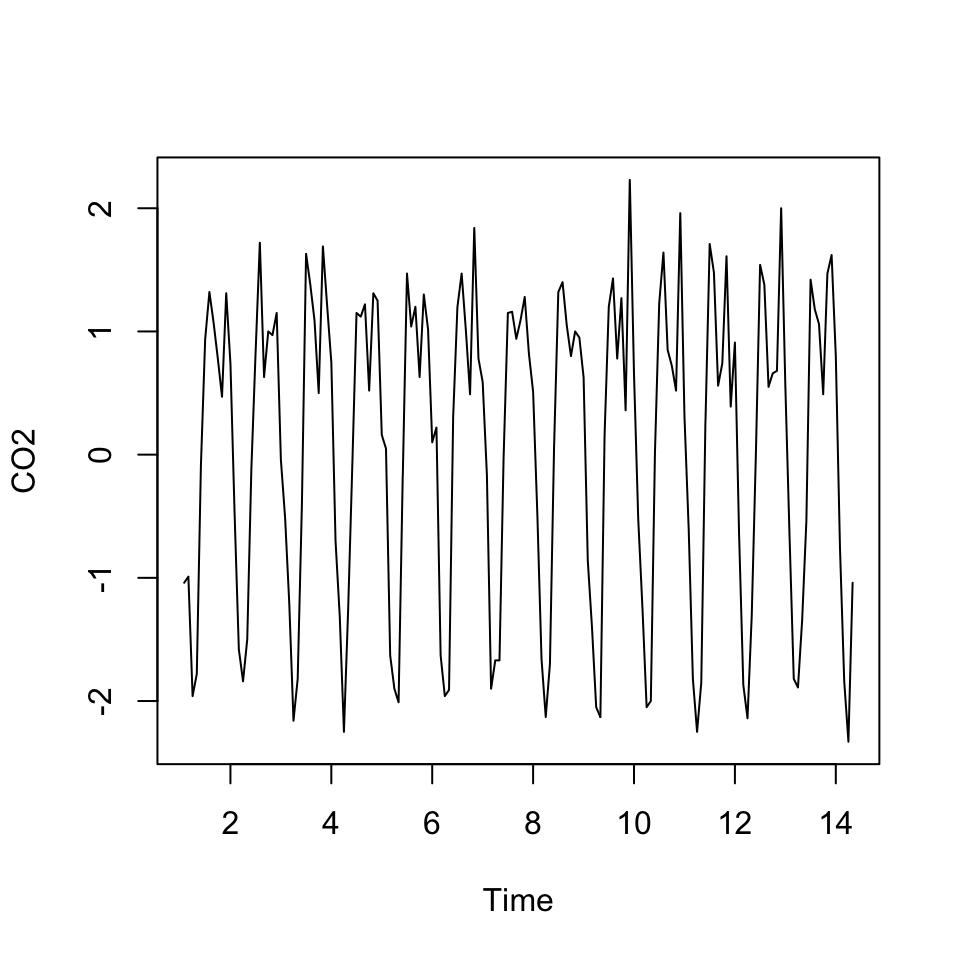
Figure 5.9: Detrending using differencing
acf(dy, 50)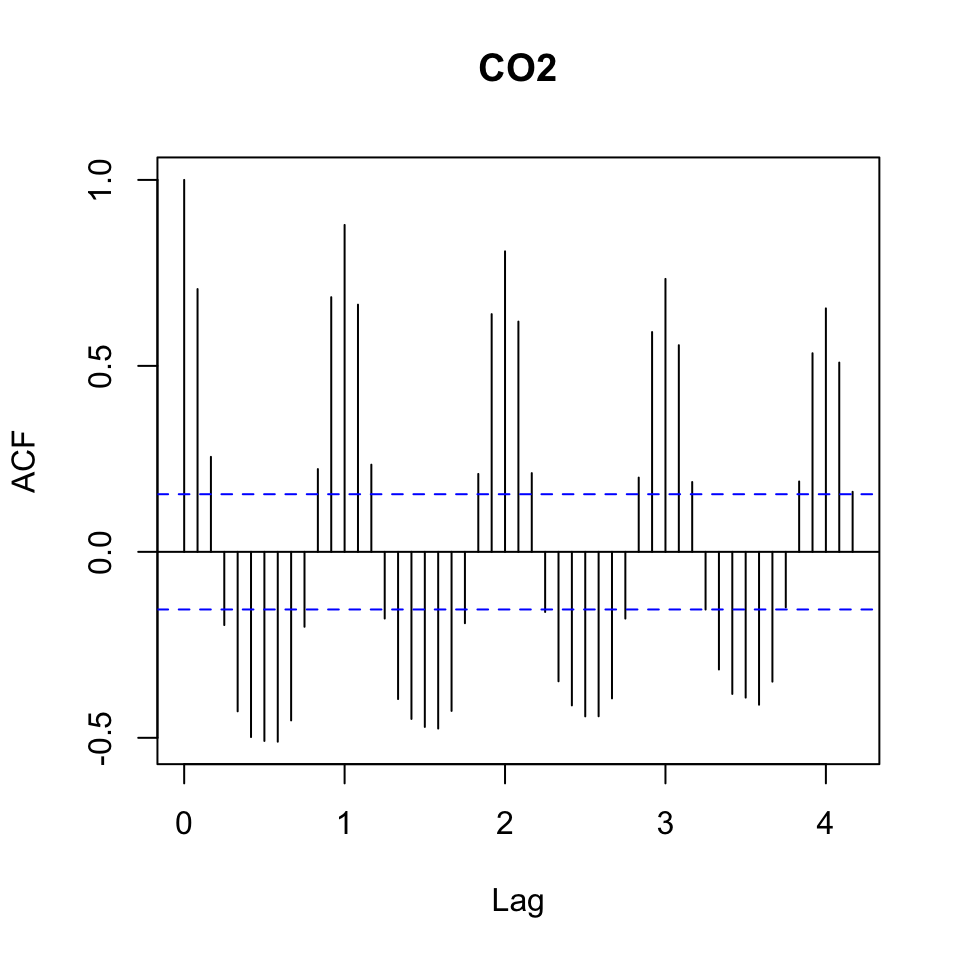
Figure 5.10: Detrending using differencing